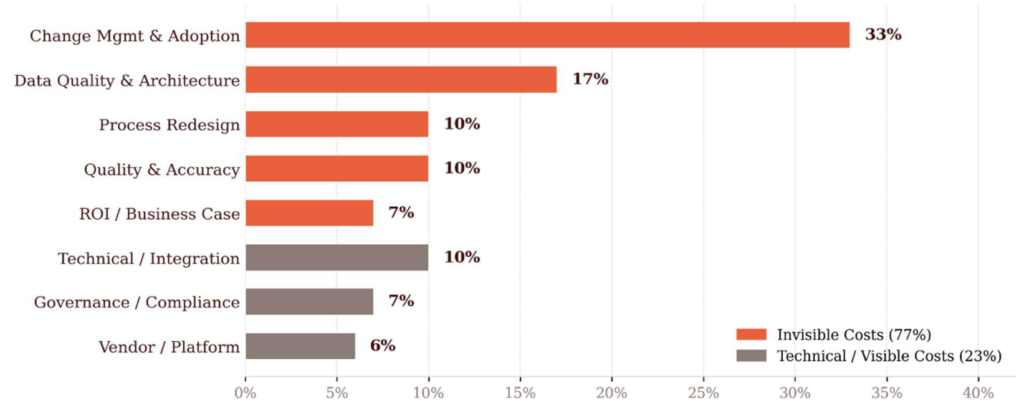
Hardest challenges in AI implementation (Pereira et al. 2026)
Wenn es um Implementation von Künstlicher Intelligenz im Unternehmen geht, werden oft nicht alle Kosten beachtet. In einer Analyse von 51 erfolgreichen Implementationen aus verschiedenen Branchen, haben Pereira, Graylin und Brynjolfsson im April 2026 herausgefunden, das 77% der Kosten, unsichtbar sind (Abbildung).
„77% of the hardest challenges practitioners faced were invisible costs: change management, data quality, and process redesign, not technical issues. Technology was consistently described as the easiest part. The true cost of a successful deployment usually includes at least one failed attempt, and the bulk of investment goes to everything except the model“ (Pereira et al. 2026).
Es zeigt sich auch hier wieder, dass der Einsatz von Künstlicher Intelligenz über den Hype hinaus auch wirtschaftlich genauer betrachtet werden muss. Das ist bei Kleinen und Mittleren Unternehmen (KMU) besonders wichtig, da KMU oft nur stark begrenzte Ressourcen zur Verfügung stehen.
Wenn man sich die vielen Meldungen in den Medien ansieht, kann man zu dem Schluss kommen, dass es (fast) allen um Aufmerksamkeit, und damit auch um Beeinflussung geht. Dahinter können wirtschaftliche, politische oder soziale Interessen stecken. Viele gehen dabei sehr subtil vor, indem sie Daten nicht genau wiedergeben, oder bewusst aus dem Zusammenhang nehmen.
Oft fehlt bei den Angaben auch die genaue Quelle. Es wird von einer diffusen Studie gesprochen oder geschrieben, doch wird die Quelle nicht genannt. Weiterhin steht bei Zeitungsartikel oft der Hinweis, dass der Beitrag auf Basis von Inhalten anderer Medien geschrieben wurde – diese werden allerdings im Text – wenn überhaupt – nicht deutlich kenntlich gemacht.
Die wenigen Beispiele zeigen schon auf, dass eine mehr wissenschaftlich basierte Arbeit wünschenswert wäre. Die Prinzipien einer solchen Arbeit würden helfen, zwischen eigener Meinung und Quelle zu unterscheiden, um sich ein eigenes Bild machen zu können. Damit kommen wir zur Akademischen Integrität, die es ermöglichen soll, dass wissenschaftlich korrekt und damit transparent gearbeitet und veröffentlicht wird. Gerade in Zeiten von Künstlicher Intelligenz muss das ganz besonders beachtet werden.
Was ist unter Akademischer Integrität zu verstehen?
Dazu habe ich eine Definition der International Centre for Academic Integrity [ICAI] gefunden, die eher im amerikanischen Umfeld genutzt wird. In Europa beziehen sich akademische Institutionen eher auf die Definition der ENAI:
The definition from the European Network for Academic Integrity [ENAI] (2022) is less philosophical than ICAI’s. ENAI states that academic integrity is: Compliance with ethical and professional principles, standards, practices and consistent system of values, that serves as guidance for making decisions and taking actions in education, research and scholarship.“ (Gallant, T. B. ; Davis, M. Khan, Z. R. (2026): ACADEMIC INTEGRITY IN THE AGE OF AI. DOI 10.1017/9781009672078).
Wenn wir unterstellen, dass akademische Integrität bedeutet, selbst verantwortlich, transparent und ethisch zu arbeiten wird klar, dass sich diese Vorgehensweise dann auch auf die Gesellschaft auswirkt.
Es wird Zeit, dass alle Akteure in einer von Künstlicher Intelligenz getriebenen Welt, akademische Prinzipien berücksichtigen. In Europa haben wir erste Ansätze dazu, die oftmals platt mit Regulierung gleichgesetzt werden. In den USA oder China erodieren diese Grundlagen eher. Es ist daher gut, dass wir in Europa einen eigenen Weg gehen, bei dem die Gesellschaft im Mittelpunkt steht.
Sogar in unseren Blogbeiträgen haben wir von Anfang an darauf geachtet, zwischen Originaltexten mit Quellenangaben, und unserer eigenen Meinung zu unterscheiden. Dass ich die Prinzipien bei meiner Dissertation und bei meinen verschiedenen wissenschaftlichen Paper einhalte, versteht sich von selbst. Aktuell beispielsweise für die beiden Paper, die ich für die MCP 2026, 16.-19.09.2026, in Balatonfüred, Ungarn vorbereite.
Zur MCP 2026 Conference zu Mass Customization and Personalization findet vom 16.-19.09.2026 in Balatonfüred, Ungarn, statt. Auch zu dieser Konferenz habe ich Abstracts eingereicht, die in der Zwischenzeit bestätigt wurden.
It is our pleasure to inform you that your abstracts entitled:
Open-Source AI for Open User Innovation: Designing a Personalized Framework
Digital Sovereignty and Open-Source AI: A European Path for Innovative SMEs
were positively reviewed by MCP 2026 Scientific Committee and accepted to proceed to the next stage of uploading full paper according to the template.
Nun geht es daran, das Paper bis zum 31. Mai 2026 nach den Konferenzvorgaben fertigzustellen.
Wenn alles klappt, werden ich beide Paper im September auf der Konferenz vorstellen, und mit den Kollegen diskutieren.
In mehreren Blogbeiträge habe ich verschiedene Aspekte aus einem Kurzlehrbuch thematisiert, das als Download zur Verfügung steht: Es freut mich besonders, dass darin herausgestellt wird, dass Open Source AI gerade für Kleine und Mittlere Unternehmen (KMU) geeignet ist, Digitale Souveränität im Unternehmen zu erzielen. Am Ende des Kurzlehrbuchs fassen die Autoren die fünf wichtigsten Punkte noch einmal zusammen:
Mittelstand Digital Fokus Mensch (2026): Digitale Souveränität als Basis für sichere KI-Anwendungen | PDF.
(1) Die Arbeitswelt verändert sich – wir müssen uns mit verändern.
(2) Generative KI kann schon bei kleinen Aufgaben große Wirkung entfalten.
(3) Die Entscheidung für KI ist individuell – ebenso die Wahl der passenden Anwendung.
(4) KI-Nutzung erfordert rechtliche Orientierung – insbesondere im Hinblick auf den EU AI Act.
(5) Menschen müssen Teil der Lösung sein – sowohl bei KI als auch bei Cybersicherheit
AI (Artificial intelligence) AI management and support technology in the Business plan marketing success customer. AI management concept.
Die Nutzung von KI-Modellen ist im privaten und unternehmerischen Umfeld angekommen. Dabei ist es für Kleine und Mittlere Unternehmen (KMU) entscheidend, ob sie sich in die Abhängigkeit der proprietären KI-Modelle begeben, oder mehr Wert auf die eigene Datenhoheit legen. Gerade KMU können es sich nicht leisten, hier knappe Ressourcen zu verschwenden.
Wenn es um Digitale Souveränität geht, und darum, leistungsfähige KI-Modelle mit eigenen oder anderen Daten zu verknüpfen, bietet das MCP-Protocol in der Zwischenzeit sehr spannende Möglichkeiten.
„MCP (Model Context Protocol) is an open standard from Anthropic designed to establish seamless interoperability between LLM applications and external tools, APIs, or data sources“ (Source: Langflow 1.4: Organize Workflows + Connect with MCP).
Wie das beispielsweise mit Langflow möglich ist, habe ich in verschiedenen Blogbeiträgen erläutert. Im Zusammenhang mit Open Source AI bietet das MCP einen Rahmen für ein eigenes, innovatives KI-System, bei dem Sie die Datenhoheit haben.
„Open-Source-Sprachmodelle sind die natürliche Ergänzung zu MCP. Während MCP den sicheren Rahmen vorgibt, liefern Open-Source-Modelle die Freiheit, diesen Rahmen nach eigenen Bedürfnissen zu gestalten“ (Hennekeuser, D. (2026): Model Context Protocol (MCP) und Open-Source-Sprachmodelle: Die Eröffnung neuer souveräner Wege. In Mittelstand Digital Fokus Mensch (2026): Digitale Souveränität als Basis für sichere KI-Anwendungen).
Unternehmen sind oftmals in einem oder mehreren Netzwerken aktiv,. Solche Kooperationen setzen dabei auf den klassischen Datenaustausch. Modernere Versionen der Kooperationen im KI-Zeitalter, speisen ihre Daten in KI-Modelle ein. Dabei kommt es darauf an, die eigene Datenhoheit zu behalten.
„Um ihre Datenhoheit zu bewahren, setzen Unternehmen auf föderierte, dezentrale Trainingsansätze. Die Daten werden hier nicht zu einem zentralen Server gesendet, sondern lokal in eine Kopie des KI-Modells eingespeist. Statt der Daten werden dann nur abstrakte Parameter zwischen den Partnern ausgetauscht. Jeder Partner kann der KI Daten zur Verfügung stellen, ohne diese den anderen Unternehmen preisgeben zu müssen“ (Fraunhofer, Forschung kompakt, 01.04.2026).
Das Fraunhofer-Institut für Software- und Systemtechnik ISST in Dortmund hat gemeinsam mit dem Industriepartner Fujitsu Research sogar eine Lösung für das Unlearning für dezentrale, föderierte KI-Kollaborationen entwickelt.
Dabei geht es um die Frage, wie mit Daten umgegangen wird, wenn die KI-Kooperation verlässt – spannend. Wie das alles funktioniert, zeigt das Fraunhofer Institut auf der Hannover Messe 2026.
„Many have claimed that training large language models requires copyrighted data, making truly open AI development impossible. Today, Pleias is proving otherwise with the release of Common Corpus (part of the AI Alliance Open Trusted Data Initiative)—the largest fully open multilingual dataset for training LLMs, containing over 2 trillion tokens of permissibly licensed content with provenance information (2,003,039,184,047 tokens)“ (Source).
In der Zwischenzeit wurde Common Corpus schon mehr als 1 Millionen Mal heruntergeladen. Der starke Anstieg der Downloads zeigt eine relative Verschiebung auf dem KI-Markt, denn immer mehr Marktteilnehmer suchen nach Open Data, die sie frei nutzen können.
„Open-Source-Datensätze wie das Common Corpus bieten hier eine Lösung. Sie ermöglichen es Forschern und Unternehmen, auf eine breite Palette von Daten zuzugreifen, ohne sich über komplexe Lizenzfragen oder potenzielle Urheberrechtsverletzungen Gedanken machen zu müssen“ ( Common Corpus übertrifft eine Million Downloads und hebt Bedeutung von Open Data für KI hervor, Mindverse vom 12.03.2026).
Langsam aber sicher wollen immer mehr KI-Nutzer Künstliche Intelligenz gesellschaftlich verantwortungsvoll nutzen – ganz im Sinne einer Digitalen Souveränität.
Es ist an der Zeit, die Entwicklungen bei Artificial Intelligence (Künstlicher Intelligenz) auch einmal etwas kritischer zu beleuchten. Zwei Forscher aus den Bereichen der Sprach- und Sozialwissenschaften haben das in ihrem Buch getan:
Bender, E. M.; Hanna, A. (2025): The AI CON. How To fight Big Tech´s Hype And Create The Future We Want | Link.
Um das Buch mit seinen Ansichten besser verstehen zu können lohnt es sich, kurz auf in die Anfänge von Artificial Intelligence zurückzuschauen. Den Begriff „Artificial Intelligence“ prägte McCarthy für den Dartmouth Workshop im Jahr 1956. Darüber hinaus hat Minsky im gleichen Jahr sein einflussreiches Paper zu Heuristic Aspects of the Artificial Intelligence Problem veröffentlicht. Seit dieser Zeit hat die Entwicklung von Artificial Intelligence immer dynamischer zugenommen.
Die Dynamik ist seit 70 Jahren auch geprägt von militärischen Anforderungen und von Investoren, die in Artificial Intelligence eine sehr lukrative Story sehen, die uns erzählt, dass Maschinen (Artificial Intelligence) im Vergleich zu Menschen in allen Bereichen besser sind, bzw. sein werden. Denn: Wenn etwas heute noch nicht klappen sollte, dann wird es mit besseren Maschinen bestimmt in der Zukunft funktionieren – so zumindest die Story. Man muss eben daran glauben…
Dieses Narrativ hilft natürlich die enormen Investitionen zu schützen, und weiterhin viel Geld zu verdienen. Doch stellen sich immer mehr Personen – und ganze Gesellschaften – in der Zwischenzeit die Frage, ob diese Erzählung stimmt, und ob diese Entwicklungen gut für die Menschen sind. Manche argumentieren, dass es sich bei dem allseits propagierten AI-Hype ehr um eine AI-Hybris handelt:
Die Hybris (altgriechisch für Übermut‘, ‚Anmaßung‘) bezeichnet Selbstüberschätzung oder Hochmut. Man verbindet mit Hybris häufig den Realitätsverlust einer Person und die Überschätzung der eigenen Fähigkeiten, Leistungen oder Kompetenzen, vor allem von Personen in Machtpositionen. (Quelle: vgl. Wikipedia).
Wenn Sie sich diese ganzen Punkte noch einmal vergegenwärtigen, kommen Sie möglicherweise auch zu dem Schluss, dass man gegen das etablierte Narrativ etwas unternehmen sollte/muss. Genau das haben die beiden Autoren mit ihrem Buch gemacht.
Um es noch einmal deutlich zu machen: Es geht nicht darum, Artificial Intelligence zu „verteufeln“, sondern darum, die Möglichkeiten von Artificial Intelligence im Rahmen von Werten und Grundrechten für Menschen zu nutzen.
Seit mehreren Jahren gehen wir auch positiv kritisch mit den Möglichkeiten und den Risiken von Artificial Intelligence um – ganz im Sinne einer Digitalen Souveränität.
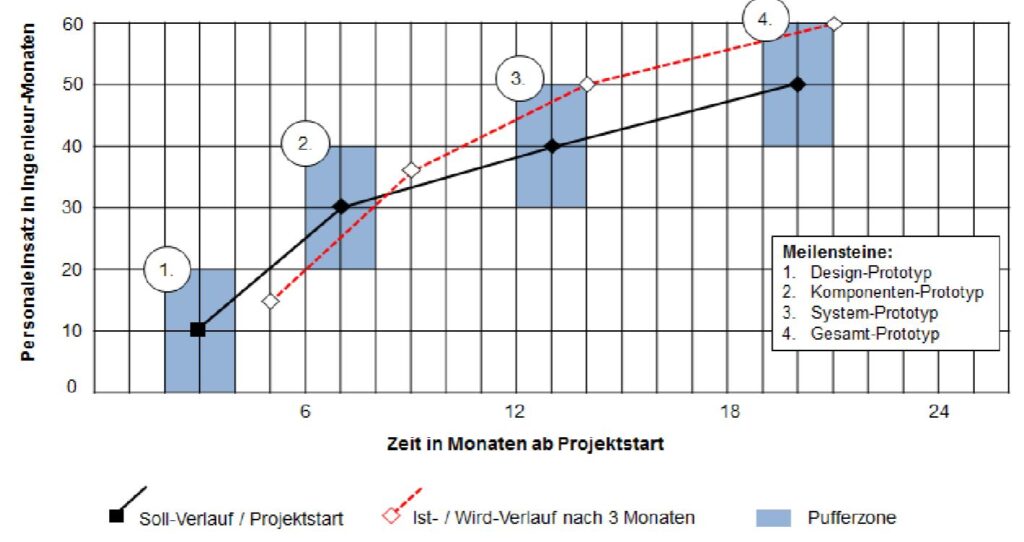
Der aktuellen Projektstand und der prognostizierte zukünftige Verlauf eines Projekts können unterschiedlich visualisiert werden. In der Abbildung sehen Sie beispielhaft auf der Y-Achse Personentage in Ingenieurstunden und Zeit in Monaten ab Projektstart gegenübergestellt.
Weiterhin sind der Soll-Verlauf (schwarze Linie) und der Ist-Wird-Verlauf nach 3 Monaten (rote Linie) zu erkennen. Die Meilensteine 1-4 sind in einer Pufferzone (blau markierte Kästchen) positioniert. Diese zeigt an, welche Abweichungen noch toleriert werden.
Die anfänglichen Abweichungen werden wohl bei den Meilensteinen 3 und 4 wieder korrigiert, sodass die geplanten Werte am Rande der Pufferzonen liegen. Siehe dazu auch
Mit Explainable AI (XAI) sollen KI-Systeme transparent, nachvollziehbar und überprüfbar gemacht werden. in dem Zusammenhang kommt dem Reasoning eine besondere Rolle zu:
„Unter Reasoning versteht man den Prozess, bei dem ein KI-System seine internen Schlussfolgerungen sichtbar macht, etwa in Form logisch strukturierter Argumentationsketten oder textuell formulierter Teilschritte (sogenannter Chains-of-Thought)“ (Mittelstand Digital Fokus Mensch (2026): Digitale Souveränität als Basis für sichere KI-Anwendungen).
XAI und Reasoning ermöglichen es gerade Kleinen und Mittleren Unternehmen die jeweiligen Prozessschritte zumindest teilweise nachzuvollziehen.
„Transparenz allein genügt nicht, wenn die Systeme nicht kontrolliert, erweiterbar und datensouverän betrieben werden können“ (ebd.).
Gerade KMU sollten darauf achten, wenn sie Künstliche Intelligenz in ihre Prozesse einbinden wollen. XAI, Reasoning, Open Data und Open Source AI bieten hier geeignete Möglichkeiten, einen unternehmensspezifischen Mix zu finden.
Open Data and Open Source AI – a perfect match – ganz im Sinne einer Digitalen Souveränität.
Diese Website benutzt Cookies. Wenn du die Website weiter nutzt, gehen wir von deinem Einverständnis aus.